¿Sabe la IA lo que no sabe?
Cuando nos preguntamos si una IA es capaz de reconocer aquello que no conoce, ¿a qué nos estamos refiriendo? Ya hemos visto en el post de la geometría del Perceptrón cómo comenzó el desarrollo de redes neuronales, inspirados en cómo funcionan las neuronas (de forma simplificada al menos). Con el paso del tiempo se fueron desarrollando redes más y más complejas, capaces de aprender patrones sutiles, mejores en tareas varias como el reconocimiento de voz, segmentación de objetos en imágenes, reconocimiento de objetos, clasificación, etc.
La IA basada en redes neuronales es muy potente y flexible, pero también puede ser un poco como una caja negra. Es difícil analizarla y dar respuestas simples a preguntas acerca de su comportamiento. Muchas veces es necesario prescindir de ellas por razones de seguridad, ya que métodos más fáciles de explicar e interpretables son obligatorios en ciertos sectores con alta regulación o en los que simplemente se prima ese factor por encima de la potencia. Volviendo a la pregunta, ¿sabe la IA lo que no sabe? Esta pregunta entraña un tema muy profundo, altamente estudiado y que todavía no está resuelto en su totalidad.
Cuando una red neuronal aprende, esta ajusta sus parámetros internos para minimizar una función de pérdida concreta. En la tarea de clasificación de imágenes, lo que sus parámetros ajustan es la discriminación máxima entre distintas clases de imágenes, por ejemplo reconocer gatos y perros. ¿Qué pasará cuando la red neuronal se vea expuesta a un tipo de dato distinto? Ya no obtendrá como entrada la foto de un perro o un gato, sino la de un tigre. ¿Qué respuesta dará la IA frente a esta situación totalmente nueva? Pues si no se hace nada al respecto, lo único que puede hacer la red es dar las probabilidades de que sea un gato o un perro (probablemente tienda a creer que es un gato).
La respuesta a esta pregunta es clara. La red neuronal no sabe lo que no sabe, es decir, no es capaz de ver un dato y discernir si es un nuevo concepto, algo que no ha visto nunca durante su entrenamiento.
Aquí es donde se conecta directamente con el problema de las cajas negras y la seguridad. No solo es difícil entender por qué un modelo toma una decisión, sino que además puede hacerlo con una confianza injustificada incluso cuando está completamente fuera de su ámbito de conocimiento. Este comportamiento es especialmente problemático en sistemas críticos. No detectar que un dato es desconocido implica que el modelo seguirá produciendo predicciones como si todo fuese normal
Durante la etapa de entrenamiento de la red neuronal, los datos provienen de una distribución concreta. Se establece previamente qué tarea va a resolver y eso tiene asociado unos datos concretos, posiblemente no completos. Se presupone que los datos de test, con los que evaluamos la red neuronal tras el entrenamiento, son ejemplos que provienen de la misma distribución. Estos datos nunca han sido vistos durante el entrenamiento, pero eso no significa que tengan una distribución distinta, si entrenamos con gatos y perros no podemos pretender que sepa que es un coche, ¿me explico? La detección de este tipo de datos que la red neuronal no conoce es lo que se llama detección de Out-of-Distribution, a partir de ahora abreviado como OOD.
¿Por qué queremos saber cuando un dato no pertenece a la distribución de entrenamiento?
La fiabilidad en un sistema es un factor clave al que hay que prestar atención, y muchas veces, reconocer datos anómalos o no conocidos es necesario para suplir esta necesidad. Las técnicas de aprendizaje automático han avanzado muchísimo bajo la asunción de un mundo cerrado. Pese a ello, en los problemas del mundo real, estos sistemas se ven expuestos a datos que inevitablemente no pertenecen a la misma distribución que los utilizados durante el entrenamiento de estos modelos. Este tipo de datos son los ya mencionados OOD. Estas muestras pueden ser peligrosas ya que los modelos, al no saber identificar este tipo de problemas, asignan predicciones sobreconfiadas a datos que deberían rechazarse en primer lugar. Esto da lugar a sistemas vulnerables a ataques adversarios, a fallos silenciosos en producción y, en última instancia, a una pérdida de confianza en la tecnología por parte de los usuarios finales.
Existen numerosos métodos que tratan de solucionar este problema desde distintas dimensiones, la elección de uno u otro o todos ellos depende del contexto. ¿Se requiere un modelo que vaya incorporando nueva información con el tiempo según aparezca? Estamos entonces en el campo del online learning, donde el modelo se reentrena o utiliza otras técnicas para actualizar la hipótesis inicial. ¿Queremos detectar si un dato es raro para tratarlo posteriormente? Entonces podemos aplicar detección de OOD.
Un ejemplo claro de donde es crucial que un sistema incorpore este tipo de métodos es en el médico. Un modelo que no pueda detectar muestras OOD juzgará erróneamente enfermedades desconocidas y causará graves diagnósticos erróneos, ya que las clasificará como otro tipo de enfermedad que sí conoce.
Detección por la probabilidad Softmax
El método más simple posible para detectar cuando una entrada a la red es OOD es el de Maximum Softmax Probability o MSP. Las redes neuronales necesitan pasar de los logits que producen las capas finales a una distribución de probabilidad. Para ello suelen utilizar la función softmax:
\[\sigma(z)_i=\frac{e^{z_i}}{\sum_{j=1}^Ne^{z_j}}\]Esta función transforma ese vector final a un vector acotado entre $[0,1]$ y cuyos componentes sumen $1$, de forma que puede interpretarse como una distribución de probabilidad. Cada componente de ese vector final representa la probabilidad que tiene el dato de pertenecer a la clase $i$.
Este método se basa en la prueba empírica de que las redes neuronales tienden a producir una probabilidad máxima alta (de las probabilidades que hay, la más alta suele ser MUY alta en comparación al resto). Esto intuitivamente lo que nos viene a decir es que la red “conoce” ese ejemplo y por tanto se siente “confiada”. En los datos anómalos, fuera de distribución, las probabilidades suelen ser mucho más uniformes. Por tanto se define MSP como:
\[MSP(x)=max_{k}P(y=k|x)\]Es un método simple. Por supuesto hay mucho más, y más complejos, pero para ilustrar el problema de detección de OOD creo que es el mejor.
Ejemplo con código
Para ilustrar mejor el problema voy a escribir unas pocas líneas en Python, empezando por una red convolucional simple.
class ConvNet(nn.Module):
def __init__(self, in_channels: int, hidden_units: int, output_channels: int):
super().__init__()
self.block_1 = nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=hidden_units,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.Conv2d(
in_channels=hidden_units,
out_channels=hidden_units,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.block_2 = nn.Sequential(
nn.Conv2d(hidden_units, hidden_units, 3, padding=1),
nn.ReLU(),
nn.Conv2d(hidden_units, hidden_units, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=hidden_units * 7 * 7, out_features=output_channels),
)
def forward(self, x: torch.Tensor):
x = self.block_1(x)
x = self.block_2(x)
x = self.classifier(x)
return x
Esta red va a ser entrenada con el conjunto de datos de FashionMNIST, donde se representan varios tipos de prendas en imágenes de tamaño $28\times 28$ en escala de grises.

Procedemos a entrenar esta red unas pocas épocas y guardamos el modelo. Este modelo solo conoce datos de este conjunto y es capaz, según la partición de test, de clasificar con un $90\%$ de precisión cualquier otro tipo de imagen de prenda que le venga.
MSP en Python
El código para calcular los scores de MSP es el siguiente:
def compute_msp(model, loader, device):
all_msp = []
with torch.inference_mode():
for X, _ in loader:
X = X.to(device)
logits = model(X)
probs = torch.softmax(logits, dim=1)
msp = probs.max(dim=1).values
all_msp.append(msp.cpu())
return torch.cat(all_msp)
El modelo lo que devuelve en su capa final son los conocidos logits (hay métodos que trabajan directamente en este punto). Los logits, sin entrar en definiciones matemáticas que se extienden más allá de lo que quiere abarcar este post, son valores en bruto que produce la última capa de la red. La función de pérdida espera probabilidades, por ello deben ser transformados. Ahora lo que hay que hacer es pasarlo por la función softmax.
Ahora vamos a cargar los ejemplos fuera de distribución, los OOD y los ejemplos dentro de distribución, los in-distribution o ID, (ojo, los ID son ejemplos que nunca ha visto, pero sí están dentro de lo que debería conocer la red). Si el detector funciona bien, debería asignar scores mucho más altos a los datos ID.
id_test = datasets.FashionMNIST(
root=data_dir,
train=False,
download=True,
transform=ToTensor(),
)
ood_test = datasets.CIFAR10(
root=data_dir,
train=False,
download=True,
transform=transforms.Compose(
[
transforms.Grayscale(num_output_channels=1),
transforms.Resize((28, 28)),
transforms.ToTensor(),
]
),
)
Ahora calculamos el valor AUROC. Para quien no lo sepa, es una muy buena forma de medir el rendimiento del detector. Para entenderlo, primero hay que entender la curva ROC. Si fijamos un umbral y clasificamos como ID todo lo que lo supere, obtenemos una tasa de muestras ID correctamente detectadas y una tasa de muestras OOD coladas por error. Si vamos moviendo ese umbral de $0$ a $1$, cada posición nos da un par de valores distinto, y la curva ROC es el trazado de todos esos pares.
El AUROC es el área bajo esa curva. Es la probabilidad de que, tomando una muestra ID y una OOD al azar, el modelo asigne una puntuación de confianza más alta a la ID. La gracia es que, al agregar todos los umbrales posibles a la vez, no nos comprometemos con ninguno en concreto (podemos medir cómo de bien funciona el detector tanto si queremos mayor sensibilidad como si preferimos un modelo más equilibrado).
Un valor de $1$ indica separación perfecta entre ambas distribuciones, mientras que $0.5$ equivale a un clasificador aleatorio, es decir, el modelo no tiene ninguna capacidad discriminativa real.
msp_id = compute_msp(model, id_loader, device)
msp_ood = compute_msp(model, ood_loader, device)
scores = torch.cat([msp_id, msp_ood]).numpy()
labels = torch.cat([torch.ones_like(msp_id), torch.zeros_like(msp_ood)]).numpy()
auroc = roc_auc_score(labels, scores)
Los resultados obtenidos son los siguientes:
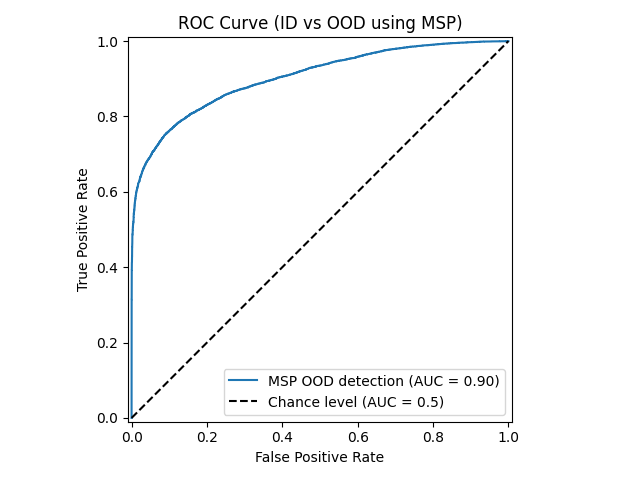
Como puede observarse, la detección con MSP es bastante buena, llegando a un valor de $0.9$. Si quisiéramos, por contexto del negocio, detectar el $90\%$ de los datos OOD, sería tan sencillo como mover el umbral de probabilidad a partir del cual se decide. Con ello, al medir AUROC para ese punto, veríamos que el ratio de falsos positivos ha aumentado. Por ello, dependiendo del contexto, hay que balancear siempre entre TPR y FPR.
Si visualizamos los scores que produce la función para datos OOD y para datos ID obtenemos lo siguiente:
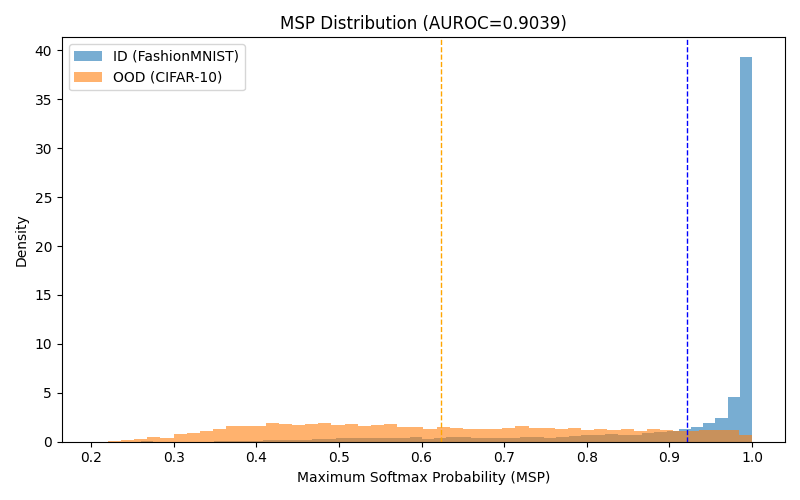
Efectivamente, hay una separación clara, con un poco de solapamiento. La red no es tan confiada con los datos OOD y por ello la distribución de probabilidades que les asigna es prácticamente uniforme. Por el contrario en datos dentro de distribución la máxima probabilidad es muy alta. Esta separación es una huella que aprovechamos para discriminar.
Otros métodos
Lo bueno que tienen métodos como MSP es que son agnósticos a la red. Puedes incluirlos en cualquier red neuronal ya entrenada y funcionará. Obviamente es un método muy simple, y sufre de muchos fallos que hacen que no sea el ideal hoy en día, pero para casos sencillos funciona bien. Para quien se haya quedado con ganas de más, recomiendo echar un ojo a la librería pytorch-ood. Posee una colección de métodos para detección OOD, así como muchas más técnicas y datasets claves para este problema. Merece mucho la pena.