Introducción
Hace ya un tiempo que quería implementar lo que vengo conociendo como la técnica teacher-student. La he visto en otros blogs, en vídeos de Youtube, en foros, etc. Siempre me ha parecido muy vistosa y bastante sencilla de implementar. La idea es simple, coges una red neuronal muy grande y tratas de copiar sus salidas mientras entrenas una red mucho más pequeña. De ahí viene el nombre de teacher-student, ya que una red (profesora) muestra sus conocimientos a otra red que la imita (estudiante). Los blogs que leía en su momento hablaban sobre minimizar la divergencia Kullback-Leibler entre la distribución de los logits del profesor y del estudiante. La distancia Kullback-Leibler, a la que me voy a empezar a referir como KL por simplicidad, cuantifica la diferencia entre dos distribuciones de probabilidad. No es una distancia (matemáticamente hablando), pero como si lo fuera para nosotros.
No era tan sencillo
Pues bien, resulta que no es tan sencillo sacarle el jugo a esta técnica. Para la escritura de estos posts suelo programar algún que otro script de Python para mostrar cómo se hacen las cosas y también para desengrasarme un poco, que al final estos posts son sobre todo para mí. El tema es, que es bastante más delicado de lo que me imaginaba. Las primeras veces tiraba de un modelo como ResNet-18 o ResNet-50 para aprender a clasificar datos del problema de CIFAR (imágenes de objetos y animales de $32\times 32$ píxeles). Muchas veces la red se sobreajustaba, lo cual es muy común en redes con demasiados parámetros (algún día hablaré de ello). Cuando una red se sobreajusta, significa que memoriza los datos de entrenamiento, los cuales incluyen ruido, lo cual hace que el modelo no rinda bien en datos nunca vistos. Eso tiene fácil solución, aplicamos early stopping. Luego, entrené a dos modelos pequeños, quizá demasiado pequeños. Uno de ellos aprendería de forma tradicional a clasificar las imágenes de CIFAR-10 y el otro imitaría al modelo profesor. Ninguno rendía bien, de hecho el que peor iba era el modelo que usaba técnicas de destilación de conocimiento. Quizá son demasiado pequeñas, pensé. Procedí a aumentar los tamaños de las redes estudiante y los resultados fueron distintos. Esta vez, la red pequeña sin destilar conseguía un resultado mejor que el profesor, incluso, mientras que la destilada era peor. En este caso puede tener sentido, si la red profesor ni siquiera supera a sus propios alumnos, ¿qué narices va a enseñar?
Tras varias iteraciones sin conseguir nada hice lo que debería haber hecho en un inicio, leer el paper original para ver si se me había pasado algo. Este artículo se puede encontrar aquí.
Sobre lo aprendido
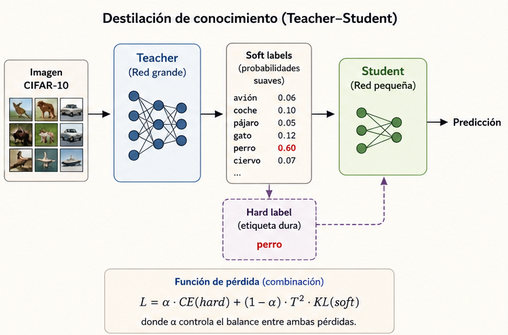
Uno de los principales conceptos que aprendí en el artículo era el de soft labels y hard labels. Las etiquetas duras son directamente las clases a predecir. Por ejemplo:
\[[0, 1, 0, 0]\]Donde la posición donde se encuentre el $1$ es la clase correcta a predecir de las cuatro que hay. En el entrenamiento más típico, con una función como la entropía cruzada, lo que se utiliza son etiquetas duras. Esta función solo se centra en maximizar la probabilidad de la clase correcta. No voy a entrar en explicar entropía cruzada, seguramente lo deje para otro post, pero para más información dejo este enlace.
Las etiquetas duras solo nos dicen qué clase es la correcta, pero no aporta mayor información. Podríamos preguntarnos, ¿cómo de similares son las clases? o ¿cuánta incertidumbre hay? Para la función de pérdida es lo mismo confundir a un perro con un lobo, que a un perro con un avión. Claramente no es un error de la misma magnitud y las etiquetas duras no nos transmiten este tipo de información.
Aquí es donde entran las soft labels o etiquetas suaves. Las soft labels son probabilidades generadas, en este caso, por el modelo profesor. Por ejemplo:
\[[0.1, 0.14, 0.7, 0.06]\]Este tipo de estructura sí permite capturar más información, más allá de si es la clase correcta o no. Aquí las clases incorrectas también aportan su granito de arena. Se pueden interpretar las probabilidades asignadas a las demás clases como una representación de las similitudes aprendidas por el modelo. Por ejemplo, si una imagen de un perro recibe también cierta probabilidad en las clases “lobo” o “zorro”, el modelo está indicando que comparte características visuales con esas categorías.
Hay un detalle importante que me dejé por el camino durante mis primeros experimentos. En la destilación de conocimiento no solemos utilizar directamente las probabilidades producidas por el profesor, sino una versión suavizada de ellas. Para ello se divide el vector de logits entre una temperatura antes de aplicar la función softmax. Cuando $T=1$ obtenemos las probabilidades normales del modelo. Sin embargo, al aumentar la temperatura, la distribución se vuelve más uniforme y aparecen relaciones entre clases que normalmente quedarían ocultas. Por ejemplo, una imagen que el profesor clasifica con un $99\%$ de confianza como “perro” podría transformarse en una distribución más suave donde también aparezcan probabilidades apreciables para “lobo” o “zorro”. Esta información adicional resulta muy valiosa para el estudiante, ya que no solo aprende cuál es la respuesta correcta, sino también qué alternativas considera plausibles el profesor. En mi implementación he aplicado un $T=4$, que suele ser bastante estándar y me ha proporcionado buenos resultados. Las soft labels del modelo profesor albergan la distribución “objetivo” que el modelo estudiante ha de aprender. Para ello se utiliza la anteriormente mencionada divergencia KL.
La combinación de ambos tipos de etiquetas produce lo que podríamos definir como sweet spot, ya que incluimos ambos tipos de codificaciones para que la optimización se nutra. No siempre más es mejor, y por supuesto podríamos usar solo las soft labels, como pensaba que funcionaba la destilación de conocimiento al principio, pero parece que funciona mejor con ambas. Para poder darle más potencia a una que a la otra, controlamos un parámetro $\alpha$, que en mi caso he dejado en $50\%$ para darle igual fuerza a las codificaciones duras que a las suaves en la función de pérdida. La función en Python es la que sigue:
def distillation_loss(student_logits, teacher_logits, labels, T=4, alpha=0.5):
soft_student = F.log_softmax(student_logits / T, dim=1)
soft_teacher = F.softmax(teacher_logits / T, dim=1)
kl = F.kl_div(soft_student, soft_teacher, reduction="batchmean")
ce = F.cross_entropy(student_logits, labels)
return alpha * ce + (1 - alpha) * (T * T) * kl
Otra cosa que he tenido que afinar al máximo es el rendimiento del modelo profesor. Al principio probé con un modelo grande y sencillo, sin muchas complicaciones, pero si el modelo es grande, es posible que necesitemos ajustar todo el pipeline de entrenamiento al máximo para poder sacarle rendimiento y huir del temido sobreajuste. En mi caso, apliqué aumentaciones de datos sobre las imágenes (cortes aleatorios sobre la imagen y giros horizontales). Estas técnicas permiten que la red observe distintos ángulos y versiones de la misma imagen, mejorando la capacidad de generalización. También se normalizaron los datos y se aplicó early stopping para poder parar el entrenamiento cuando la red dejase de mejorar. Por supuesto, esto también ha de hacerse con los modelos estudiantes.
Resultados obtenidos
Para evaluar los resultados y comparar el modelo que usa destilación de conocimiento frente al que no, presento un par de métricas importantes. Estas son la compresión y la eficiencia:
\[\text{compression} = \frac{\text{teacher_params}}{\text{params}}\] \[\text{efficiency} = \text{acc} \times \text{compression}\]La compresión simplemente nos muestra cómo de mucho se ha vuelto el modelo frente al original o profesor. A más grande, más pequeño es el modelo estudiante, menos parámetros. La eficiencia es un ratio entre la precisión y la compresión. Esta última es la más interesante y comparable, ya que permite ver si un modelo es bueno en dos dimensiones distintas. Es interesante reducir mucho el modelo y alcanzar una compresión lo más alta posible, pero si la precisión se ve afectada demasiado, quizá ya no merezca la pena seguir reduciendo. De otra forma, si la precisión se va conservando, quizá sea interesante seguir reduciendo el número de parámetros para obtener un modelo más eficiente.
Tras entrenar al profesor y a los estudiantes, se obtuvieron los siguientes resultados:
| Model | Acc (test) | Params | Compression | Efficiency |
|---|---|---|---|---|
| Teacher | 0.8865 | 23,528,522 | 1.0× | 0.886 |
| Student baseline | 0.8169 | 373,386 | 63.0× | 51.476 |
| Student distilled | 0.8688 | 373,386 | 63.0× | 54.747 |
De base, el modelo más grande obtiene un $88\%$ de precisión con $23$ millones de parámetros. Obviamente la compresión es de $1.0$ ya que es el modelo de referencia. En el caso de los modelos estudiantes (aunque en realidad uno no es estudiante de nada, se ha entrenado solito sin profesor jeje) se obtienen ratios de compresión iguales, ya que ambos tienen la misma cantidad de parámetros. Lo interesante se observa en la métrica de accuracy y de eficiencia. El estudiante que usó la técnica de destilación de conocimiento, alcanzó un $5\%$ más de precisión que la red neuronal que se entrenó de forma tradicional. De esta forma, la eficiencia es $3$ puntos superior a la del modelo sin destilación.
Este es un caso sencillo, con redes que ya de base funcionan muy bien. Quizá podría haberse entrenado aún mejor al modelo profesor, o se podría haber utilizado un conjunto de datos más complicado para aprovechar mejor esas neuronas extra. Pese a ello pueden observarse los resultados.
Nunca había probado a implementar esta técnica, y para ser sinceros, pensaba que sería mucho más sorprendente. Después de leer un poco de literatura al respecto, depende mucho del ámbito y se aprovecha mejor en entrenamientos mucho más grandes, como los que sufren los modelos de lenguaje actuales. Además, la mejora esperada suele ser leve, de un $2\%$ o $5\%$. Esta técnica es muy usada para la compresión de modelos, sin restringir sus capacidades y partiendo de modelos inmensos y probablemente altamente sobreajustados, pero claro, ¿qué es el sobreajuste cuando puedes sobreajustar el universo?. Si bien se ha hecho muy popular estos últimos años para LLMs, creo que hay mejores opciones para otros ámbitos fuera del lenguaje, como el pruning o la cuantización. Pese a ello, siempre es interesante probarlo, compararlo y saber cuándo utilizarlo si se requiere.